Left to Right: Sophia Watts, Maggie Vickers, Giovanni Gollotti, and Felix Knowlton
I am so excited to announce our 2024 cohort of Summer Research Prize winners, whose work spans a wide range of astrophysics! Now in its third year, the Summer Research Prize is awarded to support new and ongoing undergraduate research projects, and help students work closely with their mentors at the University of Washington. This prize is made possible through the generous support of our community, faculty, and friends, and has been featured in the UW College of Arts and Sciences’ Newsletter.
Now, on to our 2024 winners!
Felix Knowlton (Advisors: Jake Kurlander, Mario Jurić) High-Fidelity HelioLinC Stress-Testing for LSST Preparedness
Maggie Vickers (Advisor: Bruce Balick) Examining Density Tracers in Low-Ionization structures in Planetary Nebula
Sophia Watts (Advisors Yakov Faerman, Matt McQuinn) Investigating intergalactic filaments and sheets
Thank you to the generous community that supports truly stellar student research at the University of Washington, especially our principle donor again this year, DiRAC Advisory Board member David Brooks. You are helping the next generation of scholars to build the most advanced datasets, algorithms, and tools to explore and understand the universe!
Thanks to the generous support of the DiRAC Advisory Board, and the local UW Astronomy community, we are proud to introduce our Student Research Prize Winners for Summer 2023! This prize supports undergraduate research in astronomy at the University of Washington, providing students a stipend to focus on their independent research projects under the supervision of UW faculty and scientists. Previous winners of this prize have presented at local and national research conferences, contributed to peer-reviewed publications, and continued on to graduate school. Our summer program has also been featured in the UW College of Arts and Sciences’ Newsletter.
Celeste Hagee
John Delker
Katelyn Ebert
This year we are excited to award 5 summer prizes, including students across a wide range of astronomy and astrophysics research topics:
Katelyn Ebert (Advisor: Prof. Matt McQuinn): Precision Measurement of the Hubble Constant with Fast Radio Bursts
John Delker (Advisor: Prof. Andy Connolly): Classifying Transients with ParSNIP
Celeste Hagee (Advisors: Andy Tzanidakis and Prof. James Davenport): Building a Data-Driven Calibration Model for the Gaia BP/RP Epochal Spectra Using Supernovae
Benjamin Herrera (Advisor: Prof. Sarah Tuttle): MARVIN Optimization for Generalized IFU Use
Thank you to the generous community that supports truly stellar student research at the University of Washington, especially our principle donors David Brooks and Jeff Glickman. You are helping the next generation of scholars to build the most advanced datasets, algorithms, and tools to explore and understand the universe!
The Legacy Survey of Space and Time (LSST) is an upcoming sky survey that aims to conduct a longitudinal 10 year long survey in which answers to open questions about dark matter, dark energy, hazardous asteroids and the formation and structure of Milky Way galaxy will be searched for. To find these answers Vera C. Rubin Observatory will image, in high quality, the entire night sky every three nights. It is estimated that in the 10 years of operations it will deliver a total of 500 petabytes (PB) of data. Rubin will produce 20TB of data per night, generating a petabyte of data in month and a half. For comparison, the largest to date released astronomical dataset is the Pan-STARRS (PS) Data Release 2 (DR2). PS DR2 is the result of nearly 4 years worth of observations and measures 1.6 PB in size.
Science catalogs, on which most of the science will be performed, are produced by image reduction pipeline that is a part of Rubin’s code base called Science Pipelines. While Rubin Science Pipelines attempt to adopt a set of image processing algorithms and metrics that cover as many science goals as possible, and while the Rubin will set aside 10% of their compute power to be shared by the collaboration members for additional (re)processing, Rubin can not guarantee absolute coverage of all conceivable science cases. Science cases for which Science Pipelines produce sub-optimal measurements could require additional reprocessing as well some science cases might require a completely different processing.
Enabling processing of the underlying pixel data is a very challenging problem, as at these data volumes large supporting and compute infrastructure is required. Without considerable infrastructure it will also be impossible to independently verify whether Science Pipelines measurements are biased or not. Thinking forward, Rubin is likely not going to be the last, nor the only such, large scale sky survey. Reproducibility and repeatability are necessary for maximizing the usability and impact of Rubin data.
If pixel data re/processing were accessible to more astronomers it would undoubtedly positively impact shareability, repeatability, and reproducibility going forward and would, in general, positively impact the type and quantity of science that can be done with such data. Additionally, due to how the Science Pipelines are implemented, all of this applies to other instruments such as Sloan Digital Sky Survey (SDSS), Dark Energy Camera (DECam), Hyper Suprime-Cam (HSC), PS and more…
Modeling astronomical workflows after approach taken by the IT industry which has, in a lot of cases, significantly surpassed Rubin’s data volumes and adopting cloud based solutions allows us to resolve some of these tensions. Instead of maintaining our own compute infrastructure, we cheaply rent one. Instead of hosting datasets on our own infrastructure, where equal high-speed availability for all users can be difficult to achieve, we host it in one of many storage services offered by cloud service providers, which were designed to provide high speed access to anybody at anytime.
Rubin Data Management (DM) team is aware of these issues and commissioned an Amazon Web Services (AWS) Proof of Concept (PoC) group to ascertain what are the code base changes required to enable use of cloud services, to determine whether a cloud deployment of Data Release Production (DRP) is feasible, to measure its performance, determine the final cost of investigate other more-native cloud options for certain system components that are difficult to develop and/or maintain. The plan and its phases were described in the DMTN-114 document. The group’s members and notes from biweekly meetings can be seen on the AWS PoC Confluence pages.
Rubin Data Management architecture
The Data Butler is the overarching data IO abstraction through which all Rubin data access is mediated. The main purpose of the Data Butler is to isolate the end user from file organization, filetypes and related file access mechanisms by exposing datasets as, mostly, Python objects. Datasets are referred to by their unique IDs, or by a set of identifying references, which are then resolved through an registry that matches the dataset IDs, or references, to the location, file format and the Python object/type the dataset is to be read as. A Dataset can be fully contained in a single file but often they are comprised of combined data supplied from multiple sources.
The Data Butler architecture diagram showing how the two main components, the Registry and the Datastore, are related to each other.
Data Butler consists of two interacting but separate abstractions: the Datastore and the Registry. The system that persists, reads and potentially modifies the data sources, i.e. files, comprising a dataset is called a Datastore. A Registry holds metadata, relationships and provenance for managed datasets.
The Registry is almost always backed by an SQL database and the Datastore is usually backed by a shared filesystem. A major focus of AWS POC was to implement, and investigate issues related to, an S3 backed Datastore and a PostgreSQL backed Registry.
At the time of writing, Data Butler implementation is referred to as Generation 2 Butler. Generation 3 Butler is the revised and re-implemented version of the Generation 2 Butler that incorporates many lessons learned during implementation and use of Gen. 2 Data Butler. The description provided above, and the work described below, are all done using Gen. 3 Butler. The Gen. 3 Butler is expected to replace Gen. 2 Butler by mid of 2020.
Implementing an S3 Datastore and an PostgreSQL Registry
Science Pipelines access data purely through the Butler, therefore the file access mechanism is completely opaque to Science Pipelines. Writing a Datastore and a Registry that can interface to appropriate cloud services effectively enables the entire DRP to run while storing, reading and querying relationships directly from cloud services.
As mentioned earlier, AWS was chosen as the cloud service provider for this project. AWS is a leading cloud service provider with the widest selection of different services on offer. The choice of AWS was mainly done to its cheap pricing and wide popularity, and therefore support. AWS services are interfaces through their official Python SDK module called “boto3”. Mocking of these services, for testing purposes, was achieved by using the “moto” library. The AWS S3 service was to back the Datastore and the RDS service for the Registry.
S3: Simple Storage Service
S3 is object storage provided by AWS. Unlike the more traditional file systems that manage data as a file hierarchy, or data blocks within sectors and tracts, object storage manages data as objects. This allows the storage of massive amounts of unstructured data where each object typically includes the data, related metadata and is identified by a globally unique identifier.
S3, specifically, promises 99.999999999\% durability as uploading an object to it automatically stores it across multiple systems, thus also ensuring scalability and performance. Objects can be stored in collections called Buckets for easier administrative purposes. Access, read, write, delete and other permissions can be managed at the account, bucket or individual object level. Logging is available for all actions on the Bucket level and/or at the individual object granularity. It is also possible to define and issue complex alert conditions on Bucket or objects which can trigger execution of arbitrary actions or workflows.
Relational Database Service (RDS) and PostgreSQL
PostgreSQL is one of the most popular open source relational database systems available. The choice to go with PostgreSQL was based on the fact that it’s a very popular and well supported open source software that suffers from no additional licensing fees usually associated with proprietary software. Additionally, a wider support of Relational Database Management Systems (RDBMS) was desired as, at the time, the implemented registries were backed by SQLite, an open source but relativey poor-on-features DB, and Oracle, a powerful but proprietary RDBMS. To launch and configure the RDBs the AWS Relational Database Service (RDS) was used.
S3Datastore
The first tentative S3 datastore implementation was written in March 2019. The tentative implementation revealed a major issue with how Uniform Resource Identifier (URI) were manipulated. After expansive discussions, and an example re-implementation called S3Location to demonstrate the issues, in May 2019 a new ButlerURI class resolved the problems. During the initial implementation of the Butler it was assumed that a shared file system is the only datastore mechanism that will be used. Every call to OS functionality in the Butler module had to be changed to the new interface (Butler, Config, ButlerConfig, YAML Loader etc.). Naturally, now that this interface exists, it will be much easier to amend the existing functionality and adapt the code in the future.
Formatters, the interfaces that would construct Python objects from the data in the files, received a revision also. Changes were made to nearly every formatter (JsonFormatter, PickeFormatter, YamlFormatter, PexConfigFormatter and the generic abstract class Formatter) in the data management code base. Changes allowed them to construct objects not only from files, but also by deserializing from bytes. Since many of the objects in the Rubin code base support serialization to bytes almost none of them need to be downloaded and saved to a temporary file before opening, but can be constructed from memory instead. This applies more generally, than just to AWS, too. For example, due to the chnages made downloading the data via HTTP request avoids the need to persist the data locally.
The S3 Datastore was accepted and merged into the master branch shortly after that in PR-179. The S3 Datastore implementation demonstrated that significant portions of datastore code is, or can be made, more general. This prompted a major code refactoring to avoid code duplication leaving the entire code base cleaner in the end.
PostgreSQL and RDS Registry
When the AWS PoC Group started Oracle backed registry was a fresh addition to the DM code. Because Oracle and PostgreSQL are normatively very similar, the initial implementation of PostgreSQL registry was based on it. SQLAlchemy was used to interface with the DBAPIs. There was one new problem and a one previously known one that affected the new registry. One was the camel case table naming convention, where neither Oracle nor PostgreSQL allow uppercase table or column names. The other one were missing SQL expression compilers for views, which are not correctly created by SQLAlchemy for neither PostgreSQL nor Oracle RBMS. Once view compilers were written PostgreSQL registry was re-implemented in terms of the more general SQL registry class.
On of the bigger issues during development was the data model complexity. Because data is so difficult to mock a decision that integration tests are run against handpicked prepared real data. This data is usually bundled in a continuous integration module named after the instrument that recorded it; the canonical one being the ci_hsc containing data created by the Hyper Suprime-Cam on Subaru telescope. To run the integration tests existing SQLite registries were migrated to PostgreSQL in July and the processing pipeline was executed against it.
Integration testing revealed a major issue. As was described above, the Datasets can actually consist of multiple different building blocks, each of which is also treated as a Dataset. This means that if some processing produces a new Dataset and ingest in into the data repository, it’s not known in advance whether the dataset, or one of its constituent parts, already exist in the registry. Instead of issuing many select queries to check for existence, DM code instead relied on catching unique, primary and foreign key constraint failures to catch these edge cases. A roll-back of the single failed transaction is issued and only the parts of the dataset that are new would then be inserted. This was an intentional optimization as majority of ingest operations ingest new datasets, ergo such constraints are rarely triggered.
In PostgreSQL, however, if a single statement in a transaction fails, all previous and future statements in that transaction are invalidated too. This means that in case of a failure it would be necessary to run all previously executed statements in that transaction too, then fix the broken statement and re-executing it. Technically speaking, this seems to follow the SQL standards more closely, but almost none of the other RDBMS’s implement it in this way.
A stopgap solution, based on issuing a savepoint statement between every SQL statement and then issuing an explicit rollback to that savepoint, which works for all currently implemented registries, was implemented in PR-190 and a more complete solution, based on on-conflict SQL statements, was implemented in PR-196. The PostgreSQL registry implementation was merged into the master branch of Gen. 3 Butler in PR-161.
RDS performance issues
What we want in the end is to be able to run the complete DRP on a dataset, on a cluster of AWS instances, using AWS S3 and RDS services. Skipping slightly ahead of how we achieved this execution and how the workflow is executed, there is an important lesson regarding PostgreSQL views that was learned and I want to share.
The DRP workflow is defined by a Directed Acyclic Graph (DAG). The Rubin DAG, so called QuantumGraph, is basically an XML file that sets the order of execution of commands, their compute requirements as well as the datasets they need and datasets they produce. In this way none of the commands that require data produced by some other command will be executed before it, and none of the commands will execute on instances with insufficient resources.
The QuantumGraph is created by issuing a very large SQL statement that, effectively, creates a Cartesian product between many, of the 15-ish or so, tables in the registry. From that product it then sub-selects the relevant datasets, based on what tasks were defined in the workflow configuration, and creates the XML DAG. The results are then parsed in Python and a slew of many different, small, follow-up queries are issued. This diverse workflow presents a very difficult challenge in DB optimization. Still, the Rubin DM team reports that it takes them on average 0.5 to 1.5h to create QuantumGraphs for larger datasets on their infrastructure, the difference attributed to how complicated the workflow is. In our tests we were unable to create even the simplest QuantumGraphs even when doubling on the available resources and were forced to abort multiple times after 30+h of execution.
The lack of performance did not seem related to hardware limitations but SQL ones instead. Further inspection then revealed that the fault lied in PostgreSQL views. PostgreSQL, and Oracle, regularly collect statistics on database objects used in queries. These statistics are then used to generate execution plans. These execution plans are then oftentimes cached. This in general results in performance gains. But because Butler generates all SQL dynamically there are no guarantees that a cached, or even prepared execution plans can be executed. In PostgreSQL many of these optimizations then fail. When the views are part of larger statements they often get materialized completely, even if the outer statements have strict constraints on them.
The performance penalty was debilitating where even a simple query such as:
select * from visit_detector_patch_join limit 4;
took up to 12 seconds (for 4 results!). After moving the views to materialized views, and adding triggers to recreate the materialized views on any insert that would update them the same statement executes in 0.021 miliseconds. However, even after the changes, the simplest QuantumGraphs still took 40 minutes to an 1h to create. Indexing and several further memory related optimizations then reduced the time it takes to create a QuantumGraph for an entire tract (a small subset of a night) to under 2 minutes. Recently the SQL schema and data model for the registries was reworked and completely re-implemented, completely removing views from the schema.
What does this get us and what can we do with it?
Processing is invoked via the pipetask command, explained bellow. Output logs show calibration steps performed alongside with their measured metrics.
What all of this gives us is an ability to run Science Pipelines (instrument signature removal, image characterization, image calibration, source detection, image differencing, coaddition…) from a local machine, or even better yet an AWS compute instance where the data repository is hosted in an S3 Bucket and the registry is backed by an RDS PostgreSQL database. The above described code changes give us this ability, natively from within the Rubin Science Pipelines themselves. Now that the processing is able to execute from a single machine, we want to learn how we can employ the cloud resources to scale out and process many datasets simultaneously.
Scaling the processing.
The second major effort of the AWS POC group was focused on how do we scale the processing in the cloud to (reasonably) arbitrary sized clusters of instances. This problem is multifaceted. A part of the problem was already briefly described above: how to organize execution so that no actions, that require products of a previous action(s), are executed before former actions complete. Another facet of the problem is how do we actually automatically procure compute resources in the cloud, and how do we configure said instances.
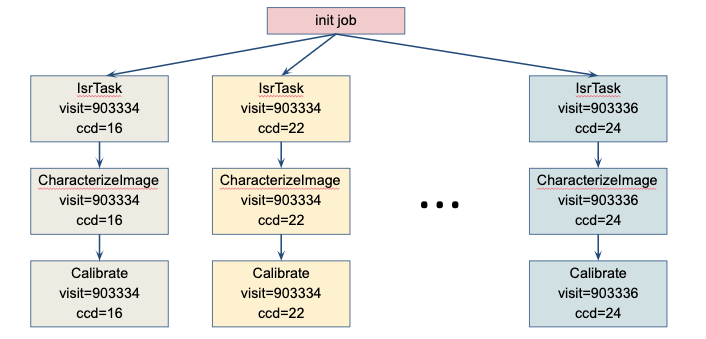
Science Pipeline workflow
A simple workflow that processes raw exposure into calibrate exposures. Along the way it detects sources and performs astrometric and photometric measurements.
Briefly, the DPR was already imagined as a Directed Acyclic Graph (DAG) execution. To execute a workflow users target datasets and a single or multiple different Tasks such as calibration, source detection etc. Each Task can be given some configuration and the entire pipeline is given general information about the data repository, such as were the root of the datastore is and at what URI can the registry be connected to. All these configurations are provided in YAML format. The workflow machinery churns out the dependencies and creates a simple DAG that is then executed. The Rubin DAG is called the QuantumGraph and its role is to organize the order in which processing needs to occur. The command invoking this whole machinery is called a pipetask to show it’s not as scary as it sounds here is an example:
pipetask -d 'visit.visit=903334' # IDs or references to datasets we want to process.
-b 's3://bucket/butler.yaml' # Data repository config file (where the datastore/registry is etc.)
-p lsst.ip.isr # List of packages containing tasks that will be executed.
-i calib,shared/ci_hsc # input dataset collections required (flat, dark, bias exposures etc.)
-o outcoll # Name of the output collection, i.e. where the results will be stored
run
-t isrTask.IsrTask:isr # Tasks to execute,
-C isr:/home/centos/configs/isr.py # and a config for each task
In this case we target a single task – the instrument signature removal task. Note how the data repository does not need to be local but that it’s possible to target configuration hosted on S3.
HTCondor and condor_annex
HTCondor is a popular open source distributed computing software. Simplified, it is a scheduler that executes jobs submitted to its queue. Each job has a submit script that defines which queue it is placed in, what are the jobs resource requirements, where should errors be redirected to etc. Typical environments in which HTCondor is most often run are co-local compute resources with a shared, or networked, filesystems.
Thankfully however, HTCondor clusters can be configured very flexibly. A module called condor_annex extends the typical functionality of HTCondor by adding in cloud resources. It currently supports AWS only but Google Compute Engine and Microsoft Azure will be implemented shortly. Using condor_annex we can take advantage of the AWS’s Elastic Compute Service (EC2) to procure computational resources on which jobs in HTCondor’s queue can execute.
Example of terminal status output of a condor cluster using EC2 compute instances executing a DAG submitted through Pegasus.
To execute the QuantumGraph on the cluster procured by condor_annex a workflow management system called Pegasus is employed. In the future, as the pipetask workflow matures, this package might not be required anymore, but for now think of it as the interface that converts the QuantumGraph into submit scripts and adds them to HTCondor’s cluster queue in the correct order.
Pegasus status detailing the DAG currently being executed. The workflow is processing raw images into calibrated exposures.
The configuration of the HTCondor cluster can be pretty tedious and complicated so the AWS POC group offers pre-prepared Amazon Machine Image(s) (AMIs) that contain the Rubin Stack, Pegasus and HTCondor with condor_annex pre-installed and configured. If you wish to see how the configuration is done, or replicate the configuration yourself, see the accompanying documents on setting up Amazon Linux 2 or Centos 7 environments and then follow HTCondor and condor_annex setup guide.
An AMI is effectively an image of the system that you want present on the EC2 instance after booting it up. It prescribes the OS, software, any additional installed packages and data that will exists on that instance. The AMIs are based on HVM and should work on all EC2 instance types, however they are still an early product and are shareable on a per-case basis. Contact dinob at uw.edu for access to the AMIs.
Conclusion
At the time of writing the scalability, pricing and usability are still being evaluated. The final conclusions will be reported on in DMTN-137 but the preliminary results and behavior are very promising.
A ~35 person demo was held on November 8th at Kavli Petabytes to Science workshop in Cambridge, MA. Details of the demo, as well as more detailed explanations of the workflow accompanied by images, can be found on the tutorial website. Each attendee spun up their own 10 instance cluster and executed a 100 job workflow based on the ci_hsc data. The total cost of the demo was ~35USD.
Additional larger scale testing, so far, were performed with clusters up to a hundred r5.xlarge, m5.xlarge and m5.2xlarge. These instances have 2 to 4 cores per instance with 8 to 32GB of memory on which a tract-sized datasets were processed; a tract is a small sub-selection of a whole nightly Rubin run. Further scaling and pricing tests will be executed up to a whole nightly run at which point more qualitative performance characteristics and pricing can be established.
AWS PoC showed that it is not impossible, nor is it significantly more difficult to run the Rubin DRP in the cloud compared to setting up a local compute resource. The preliminary tests indicate that the cloud definitely has the potential for significant scaling while still remaining affordable. Given the variety of problems mentioned in the introduction, as of yet, there is almost a certainty that such functionality would be desirable and accepted in the community.
Another important AWS PoC result was exercising the DM code. While implementing the support for AWS into the DM code we discovered many assumptions that were made in the DM code. Many of these assumptions were not only limiting the implementation of the AWS support, but also made the Butler less flexible than necessary. Even if cloud aspect is not pursued further, just recounting the contributions made in return made this exercise worth while. As a result of the AWS PoC Groups work, the Butler code base is left at more general and flexible than it started.